요약
- 통계 분석은 주로 변수 간 관련성이 통계적으로 유의미한지 확인하는 것을 중점으로 둔다.(머신러닝은 새로운 값을 예측)
- 모집단의 확률 분포를 가정하는 첫 단계(가장 쉬운)는 정규분포와 선형 관계이다.
- 그러나 실제 데이터들은 비선형 관계가 대다수로 기술 통계를 통한 데이터의 분포와 특징을 파악하여 모집단의 확률 분포를 가정할 수 있다.
- 이때 도메인 데이터에 대한 사전 지식이나 다양한 확률 분포에 대한 선행 학습이 되어 있다면 더 빠르게 모집단의 확률 분포를 가정할 수 있다. 따라서 확률론에 대한 학습이 선행되어야 한다.
1. 통계학 활용
통계학 재정리
- 통계학은 기술 통계와 추론 통계로 나뉜다.
- 기술 통계는 통계량을 통해 데이터의 특징을 분석한다.
- 추론 통계는 분석한 샘플 데이터의 특징을 통해 가정한 모집단의 분포를 추정한다.
1.1 정규분포와 선형 관계
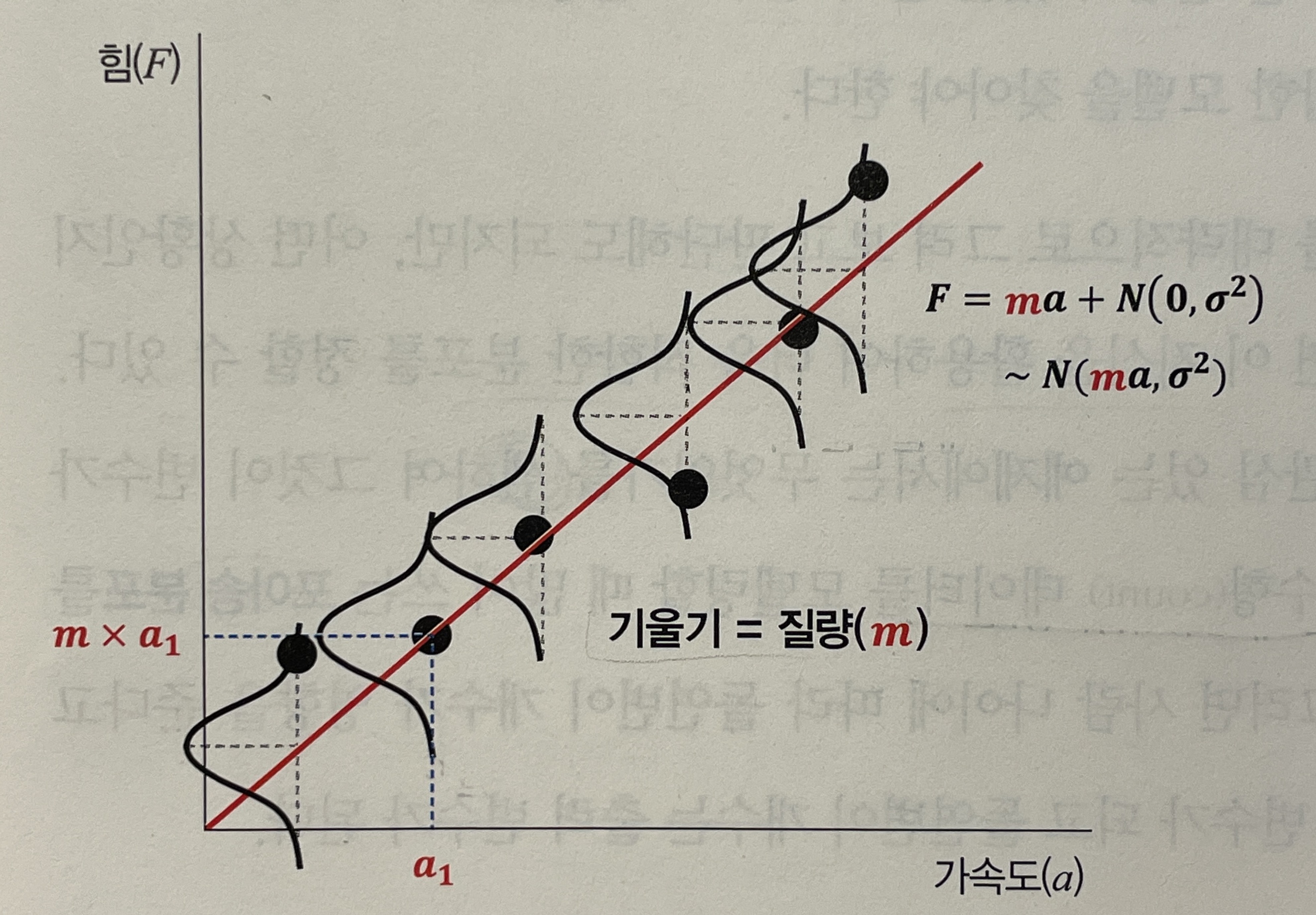
F=ma 예시
- 힘(
F)에 따라서 측정된 가속도(a) 값을 하나의 포인트로 표현한 예제 활용- 즉,
F와a는 서로 선형 관계 임을 알고 있는 상태에 질량(m)을 추론
통계 분석 관점에서 데이터를 통해 두 변수(힘, 가속도) 사이에 관계를 검증하거나, 다른 변수(질량)을 예측하는데 집중한다. 특히, 두 변수 간 관련성을 통계적으로 유의한지 확인하는 것은 통계학적인 관점이며, 새로운 값을 예측하는 것은 머신러닝 관점이다.
또한, 해당 데이터를 이용하여 어떤 확률분포가 데이터를 가장 잘 설명할 수 있을지 결정할 수 있다. 가장 쉬운 방법이 정규 분포와 선형 관계이다. 따라서 첫번째로 시도해 보는 것이 선형 모델이다.
1.2 선형 모델
선형 모델에는 정규 분포를 따르는 오류()가 포함된 모델을 의미한다. 여기서 오류()는 평균은 0, 분산은 인 정규분포 을 따른다()
해당 데이터는 평균이 인 점을 제외하면 분산이 로 동일하다. 각 포인트별 퍼져있는 정도는 동일하고, 평균값은 를 입력할 때 마다 변하고, 은 상수 값으로 학습된다. 이는 선형회귀 분석의 내용이다.
입력 변수 를 통해 상수 을 곱해 출력변수 가 된다는 내용을 학습한다. 즉, 출력변수 는 입력 변수 에 따라 정규분포를 따른다고 해석할 수 있다.
그러나, 실제 세계에서는 데이터가 비선형적인 형태인 경우가 매우 많다. 통계 분석에서는 보유한 데이터의 형태에 따라 얼마든지 변수 간 관계가 다를 수 있다. 이를 보완하기 위해 확률론이 필요하다.
2. 확률론 활용
돌연변이 개수의 합
- 출력 변수는 한 세대에서 발생하는 돌연변이 개수의 합이다.
- 해당 상황에 맞는 적합한 모델을 찾아야 한다.
통계학 중 하나인 기술 통계를 통해 데이터의 분포를 대략적으로 확인할 수 있지만, 사전 지식이 있다면 더욱 적합한 분포를 가정할 수 있다.
해당 데이터는 계수형(count) 데이터로 이러한 데이터를 모델링 할 때는 주로 포아송 분포를 사용한다. 이를 활용하여 사람 나이에 따라 돌연변이 개수가 영향을 준다고 할 때 입력 변수는 나이가 되고 출력 변수는 돌연변이 개수의 합이 된다.
이처럼 두 변수 간 관계를 확인하기 위해 선형 모델이 아닌 포아송 분포를 활용한 포아송 회귀 분석이 적합하다. 단, 무조건 계수형 자료가 포아송 분포를 따른다고 볼 수 없다. 이와 비슷한 음이항분포나 준포아송 분포 등 다양한 옵션들이 존재한다.
이처럼 상황에 따라 사용 가능한 분포의 형태가 다르기 때문에 분포의 종류를 많이 알수록 데이터에 더 적합한 모델을 선택하여 학습할 수 있다. 즉, 따라서 분석자는 여러 가능한 확률분포 옵션 중 가장 적합한 확률분포를 선택한다. 이처럼 다양한 확률분포 지식을 습득하기 위해 통계학보다 확률론을 사전학습 된다.
참고자료