요약
- 통계학은 모집단의 확률분포를 사전에 정의한 후 이를 맞추는 모델을 찾는다면, 머신러닝은 목적함수를 최적화시켜 모델을 학습하고 주로 새로운 값을 예측하는 것에 중점을 둔다.
- 모델은 훈련 데이터랑 입력 변수와 결과값인 출력 변수 간 관계를 형성하는 함수이다.
- 목적함수는 모델 내 파라미터에 따라 모델이 잘 예측하는지 측정하는 함수이며, 주로 실제값과 예측값의 차이인 비용을 최소화시키는 함수를 목적함수로 한다.
- 머신러닝 모델의 목적이 결과값의 확률 분포를 찾는 것이라면 이 문제는 우도를 측정하여 최대우도를 추정하는 통계학적 분석이 되어 서로 근분은 다르지 않다.
1. 개요
머신러닝(Machine Learning) 이란?
머신러닝은 훈련 데이터를 기반으로 목적함수를 최적화하는 모델을 학습한다. 결국 통계학습과 마친 가지로 모델을 학습한다.
목적함수란 최소화 또는 최대화시키는 대상 함수이다. 머신러닝에서는 모델을 통한 예측값과 실제값의 차이를 비용이라 정의하는데, 이 비용을 최소화하는 하도록 모델을 학습한다.
2. 통계학과의 관계
2.1 차이점
통계 모델은 분석자가 모집단이 특정 분포를 따를 것이라고 사전에 정의한 후 잘 맞추기 위한 확률분포 모델을 찾아낸다.
반면에, 머신러닝의 대표적인 기법인 뉴럴 네트워크는 입력변수와 출력변수 사이에 히든 변수를 원하는 형태로 삽입한다. (즉, 입력변수 → 히든 변수 → 출력 변수 )
이처럼 입력변수와 출력변수 사이에 관계를 형성하는 함수를 형성하는데 이를 모델( )이라고 한다. 그리고 목적함수를 최적화 시키도록 모델의 파라미터(여기서는 히든 변수())을 조정한다.
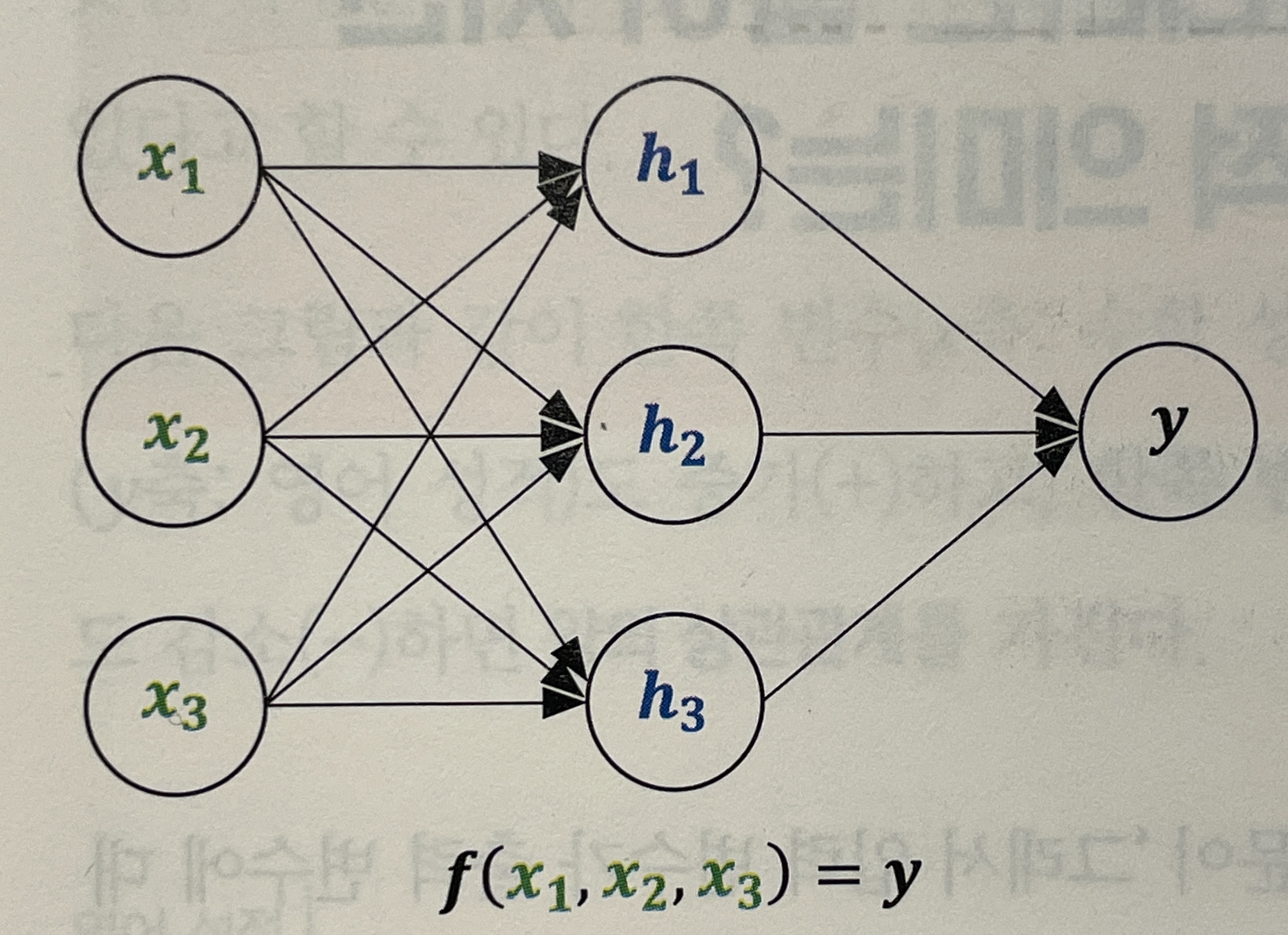
모델과 목적함수의 차이는? ( 내가 궁금해서 찾아본 것)
- 모델(Model)은 입력 변수를 통해 출력 변수(예측값)가 나오도록 만드는 함수이다. 모델은 고정되어 있고 모델 내 파라미터를 조정한다.
- 목적함수(보통 Loss Function)는 모델이 얼마나 잘 예측했는지 측정하는 함수이다. 대표적으로 실제값과 모델을 통해 예측한 값과의 차이인 비용을 최소화시키는 함수(예시: 편차제곱합)가 있다.
- 즉, 최적화란 모델의 파라미터를 변화시켜 목적함수의 최솟값을 찾는 과정이다.
- 단, 목적함수와 모델을 평가하는 평가지표는 다르다. 목적함수는 모델이 학습 과정에서 최적화되는 것이고, 평가지표는 최적화된 모델의 최종 결과를 평가한다.
2.2 연관성
위 모델에서 출력 변수()가 어떤 확률분포를 따른다고 가정한다면, 이 문제는 목적함수를 최적화시키는 문제가 아니라 우도를 계산하여 우도에 대한 최대화 문제(MLE) 로 풀 수 있다.
즉, 머신러닝에서 수 많은 변수 사이에 관계를 모델링 하였더라도 최종적으로 변수들이 특정 확률분포를 따른다고 가정한다면 결국 근본은 통계 모델을 학습하는 것과 동일하다. 이로 인해 통계적 학습과 머신러닝에서 사용하는 용어도 매우 비슷하다.
참고자료